The purpose of this study is to analyse and visualise the MOT data. These data are available on the government website (link) from the year 2005. The raw datasets are cleaned, transformed and stored in a format that enables fast analysis. Five storage methods are compared to define which one is the best. The analysis and visualisation are done using Python and the library Plotly.
Python scripts are created to query the datasets from the government website using the library "requests". The datasets are either csv or txt files, sometimes one file
per year sometimes multiple files per year. Two main datasets exist: 1) "test_result_year.csv" that contain general information about the test and the vehicle,
and 2) "test_item_year.csv" that contain information about tests that trigger warnings/faults. Other datasets include fuel type, cylinder capacity or fault location.
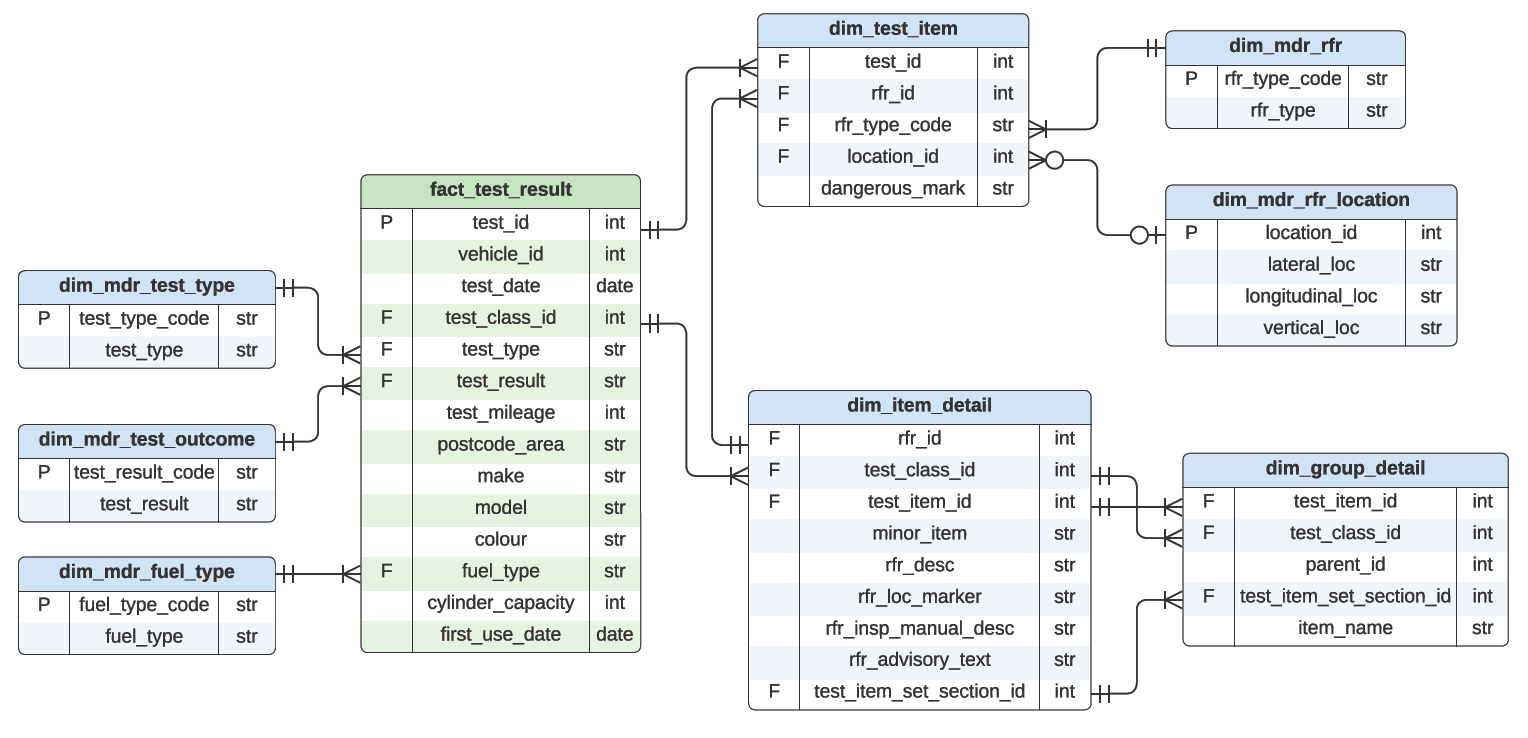
The Entity Relationship Diagram (ERD) is drawn as part of the data modelling process. The ERD helps to define the tables to be created and the relationship between them.
The Crow's foot notation is used in the ERD below.
Python script is created to load the datasets, clean the data and transform them according to the ERD.
Different solutions exist to store the data but depending on the data and the usage of them some solutions are more suitable than others. This part details the data storage comparison for these specific MOT datasets. The storage methods benchmarked are: Postgres, Parquet, Feather, HDF5, and Jay. They will be evaluated and compared against: data size, loading and storing time, and memory usage. Four files are used for this comparison, details about these files are on the table below.
| Filename | Number of rows | Number of columns |
| test_item_2005 | 9,844,489 | 5 |
| test_item_2006 | 46,030,435 | 5 |
| test_result_2005 | 7,113,089 | 13 |
| test_result_2006 | 30,302,568 | 13 |
The first comparison is about the size the datasets needs for storage. Parquet is the best format to use in terms of required space. Feather and Jay are the second and third best choices. Parquet performs better thanks to a higher compression rate. Postgres and HDF5 are the worst choice for this dataset. HDF5 seems to be more performant than Postgres until a certain value, where HDF5 needs about 70% more space to store the biggest dataset. The top 3 file formats need about 20% to 50% less space than Postgres.
Then the read and write time is compared for each file type. Jay files are the fastest to be read with a time around 1ms or less, while the others need at least 2s
in the best case. Feather and Parquet are the second and third best. The biggest Parquet file takes almost 80s with Parquet which may be due to the memory being fill up
that slows down the process. Postgres and HDF5 perform poorly and some big files do not even load after waiting for 10 minutes (that is why some bars are missing form the
graph below). Jay is a clear winner but the data are loaded as datatable format which is not widely used as Pandas dataframe and may need to be converted which can take some time.
Regarding the write time, the same three file format wins: Jay, Feather, and Parquet. Again Postgres and HDF5 do not perform well. The order of the top 3 is due to the compression rate, the more the data is compressed the more time to write it and the more time to uncompress and read it.
Finally the memory usage is compared. Postgres performance have not be recorded for this part. The memory usage for data writing data is similar amongst the file formats compared even if HDF5 performs almost always the worst. Jay files are the best from far to load the data as datatable instead of dataframe for the others. The biggest Parquet file ("test_result_2", ~1.2GB) requires a big amount of memory to load the data which can explain the long loading time observed at the previous part. HDF5 file cannot be loaded for some of the biggest files. To reduce the memory usage, dividing into small chunks can be a solution.
Three file formats appear as clear winners: Parquet, Feather, and Jay. Parquet is the best for storage required but the drawback is on the reading time. Jay files are loading the data extremly quickly but uses datatable as data type. A trade off must be defined according to the purpose of these datasets. This conclusion is valid with these specific datasets and can be different with different datasets and different purpose of data usage/analysis. Jay is not chosen due to the unknown about datatable data type and whether is can perform same as Pandas dataframe. Parquet is chosen because it is planned to migrate the data to the cloud where Parquet is a widely used and compatible format.
Multiple analysis is done. Each sections are provided with one or multiple interactive plots. Do no hesitate to select/deselect from the legend the fields for better readability and zoom in to observed better some trend. Even if the data have been pre-processed some errors inserted in the raw the datasets are difficult to correct, e.g. error in date is difficult to modify as well as wrong mileage entered at the first MOT test and carried over in the years.
The test success rate slightly increase from 2013, from 68% to 75% (considering only the outcome “P” (Passed)). The outcome “PRS” (Pass with rectification at station) combined with “P” makes an overall success rate of 80% in 2021. The failed ("F") tests are dropping from 2013 from 23% to 19% following the opposite trend of “P”. The other test outcomes are aborted tests which cumulated percentage does not exceed 1%.
In case of failed tests, some vehicles have to go though MOT test more than once. That is why for some analysis the unique vehicle id must be used to avoid counting the same vehicle more than once and biased the results. Between 22% to 26% of the tests are retests. That follows the number of failed tests of the graph above. Over the year the number of unique vehicles increases for two reasons: 1) mainly the overall vehicle stock that is increasing, 2) more MOT test centres providing test results (especially from 2005 to 2006).
The mileage per year is calculated according to the following methodology: 1) calculate for each vehicle the age in days (test_date – first_use_date), 2) calculate the overall yearly mileage (test_mileage/(vehicle_age/365)), 3) filter the max value to 100,000 miles, hence max is close to this value and min is always 0. The mean and median values are constantly decreasing over the year with a more significant drop from 2020 due to Covid. In 2021, the mean and median yearly mileage are respectively 7,974 and 7,227 miles.
The fuel type share of the vehicles tested highlights the majority of PE (petrol) and DI (diesel) vehicles. The share of PE dropped from 77% to 53% while the share of DI increases from 22% to 44% in about 15 years. Combined they represent 98% of the fuel types. The trend of higher number of alternative fuel vehicles can be seen in the last year with the portion HY (hybrid) increasing to 1.5% in 2021 (a zoom on the graph may be required). The new vehicles are exempted of MOT test for the first 3 years, hence there is a delay of 3 years of the increasing trend of alternative fuel vehicles. It is expected to see this increase growing in the next years.
The capacity cylinder is limited to 10,000cc, as values above are considered as outliers. They are probably due to errors in the original datasets. The mean and median cylinder capacity did not change a lot, respectively 1,700cc and 1,600cc in 2021 (top graph below). For the bar chart (bottom graph below), the values of 2021 have been rounded to reduce the number of bins. The top 3 cylinder capacities are 2,000, 1,600, and 1,200 with respectively 19.1%, 17.6% and 11.8%. The cylinder capacity share between 500cc and 3,000cc is below 0.3%.
The maximum vehicle age ranges from 122 to 160 years. The big age can be very old car but it can also be error in the raw data. The mean and median vehicle age is slowly increasing by 1.5 year to reach in 2021, 9.6 and 8.6 years. The vehicle age has been rounded to plot the vehicle age share for 2021 at the moment of the MOT test. Peaks are observed at the vehicle’s anniversary because the vehicle are usually tested at a date very close to the test due date.
The vehicle age is now calculated according to the end of the year. Peaks are still visible are regular period of the year, usually at the beginning of the year with the highest peak around April. According to some specialised website (autotrader, parkers, autoexpress), the best time to buy is March, September or at the end of each quarter (March, June, September, December). The cumulative distribution plot for 2005 and 2021 highlights the increasing median age observed at the previous slide. The lower the line the lower the age. In 2005, 26.2% of the vehicle were 5 years or less while it was 17.5% in 2021. In 2005, 72.4% of the vehicle were 10 years or less while it was 55.8% in 2021.
Test outcome ratio comparison for 2005 (top graph below) and 2021 (bottom graph below). There are many different OEMs which makes the visualisation not easily readable. Hence, the data are filtered to keep only the OEMs with more than 50,000 vehicles in 2005 (skips 10%) and more than 100,000 vehicles in 2021 (skips 4%). The ratio of “pass” test is calculated, it represents the vehicle that pass at the first attempt the test. Most of the other test pass at a re-test after repairs. The overall pass rate increases from 2005 to 2021. In 2005, the best OEM reaches 73% of pass while it reaches 90% in 2021. The average also increases from 64% to 80%.
Some areas have a better test outcome rate, especially in the South-East, around London. The South-West is the region with the lowest test outcome rate. More investigations would be required to understand the reasons for these differences.
The data are migrated to the cloud in Delta tables using Databricks. Similar data analysis is performed on Databricks notebook. The results are checked to be the same as the one obtained on-premises. The Databricks cluster is using the lowest characteristics available to be as close as possible to the on-premises hardware used. The data analysis done on Databricks reduces the computation time by 50% to 90% compared to the on-premises solution. It can be further decreased by using better cluster characteristics. It is observed that the higher the complexity the bigger the computation time reduction (complexity includes the number of columns queried and the processes performed).
The cloud has associated cost to consider when choosing which approach to take regarding the data storage and processing. It should be compared with the cost of purchasing hardware for on-premises solution, maintenance and labour cost to maintain the system working. Databricks runs from Azure and costed about £16 for this comparison. The cost of maintaining data and notebooks on the cloud is £0.05 per day. If the project is finished and data can be deleted there is nothing to pay unlike an on-premises solution where the hardware bought and maintenance cost still need to be paid back. It will take longer and it depends on the usage.
Jay file seems to be quite fast in terms of read/write. The only question is about the capability to use datatable data type for data filtering analysis. A simple code is used to evaluate the performance of Parquet files loaded with Pandas or Dask and of Jay files loaded as datatable. The code load “test_result” for 2005, performs a "groupby" to get the count of test outcome results. The code is run 10 times and the average of computation time is calculated. Using Jay file in this case is 50 times faster than Pandas, while Dask is 10 times faster than Pandas. This result is valid only for the operation done in this code example, some other operations may not be available with datatable or may take longer.
| Data format | Computation time [s] | Difference with Pandas [s] | X time faster than Pandas |
| Parquet (Pandas) | 12.49 | N/A | N/A |
| Parquet (Dask) | 1.24 | 11.25 | 10 |
| Jay | 0.25 | 12.24 | 50 |